Big data engineers often face a conceptual task – how to extract knowledge from the information stored. For a long period of time our company has been developing natural language processing (NLP) methods of analyzing and mining data. In our practice, we faced storages with millions of manually created documents/reports and the lack of possibilities for systemizing the information obtained at different times, in different places and without a uniform standard for presenting data.
So, how to transfer the stored information into the company’s intellectual capital?
There is no single and easy answer. Unfortunately, it’s impossible to offer a universally applicable method that would satisfy all the customer’s needs. Here it’s a must to develop a customized system for processing, storing, and extracting information. To comply with all the requirements, such development should be carried out in close collaboration with the customer.
Development starts with analysis of customer’s needs – which data he/she needs and which forms seem comfortable to present these data/this information.
Then it’s vital to perform a shallow analysis of the existing textual documents contents and their peculiarities (including lexical ones). Such analysis allows to:
- Define textual data volume;
- Recognize languages;
- Spot and (if needed) correct misspellings and grammatical errors;
- Extract unique content (recognize duplicates, including complete and semantic matching);
- Cluster textual documents with the same meaning;
- Study technical peculiarities of texts and lexical features of textual data/information;
- Define uninformative parts of documents (for instance, links to other information sources) and find out features that differ them from informative ones.
This analysis helps to have a clear picture of the information, stored by the customer, and methods of its efficient usage. On the basis of this analysis our experts choose the most appropriate semantic techniques to extract the necessary data and present them in the most comfortable way for the customer.
The quality and efficiency of semantic tools depend on the initial data quality. During the elaboration opening phase, we try to automatically clean textual documents from the existing uninformative parts. Usually we face the necessity to develop a specific filtering module.
Then, the chosen semantic techniques are customized according to the customer’s tasks and lexical peculiarities of their textual documents and the knowledge domain. Furthermore, we respond to the challenges of the documents procession, extracted data/information storage and access to them. We also develop a user-friendly interface.
We offer the following semantic methods:
Semantic index
All in all, information should be indexed and added to the semantic data base. Numerous linguistic tools work with this data base and provide knowledge management.
Database update and actualization
A separate subsystem is to deal with maintaining the database relevance. Some tasks require the usage of data within a certain period of time; some of them are sensitive to information duplicates.
Work with knowledge
It is a separate and highly customizable area, in which each client projects an individual information environment.
Intellexer semantic services include:
- Sentiment analysis – a powerful tool for analyzing feedback/public opinion, detecting problems. If you are eager to know your hotel guests’ opinion on new beds, this tool is exactly what you need;
- Named entities extraction (proper names, surnames, geographical names, organization names, etc.)and detection of the relations between them. It’s probably the most useful function that allows conducting analytical research;
- Concepts extraction – the extraction of the most important terms from the document. This feature can be used for tagging, classifications and navigation through the document;
- Comparison and categorization – in fact, it’s the same procedure that allows comparing one textual document with another document, or a number of documents. The peculiarity of this function is that we can compare the texts at the level of semantic meanings, not just the key words;
- Summarization. Thanks to this tool we get an abstract of the necessary size that would take into account the general meaning of the text;
- QAS allows making questions in natural language and finding answers in the database;
- Intellexer Natural Language Interface gives users the possibility to interact with the databases and search engines using natural language. The script analyzes the user’s query and converts it into one or a couple of queries for the database, using Boolean expressions, synonyms, spell checking, etc.
Quick and easy work around
What does the customer get in the end? We won’t enumerate advantages; we’d better give a vivid example. From dozens of thousands of documents in different formats (doc, ppt, and pdf), located in more than 500 folders, main Named Entities and concepts were extracted. On their basis ontology has been created that is used to navigate quickly through the documents.
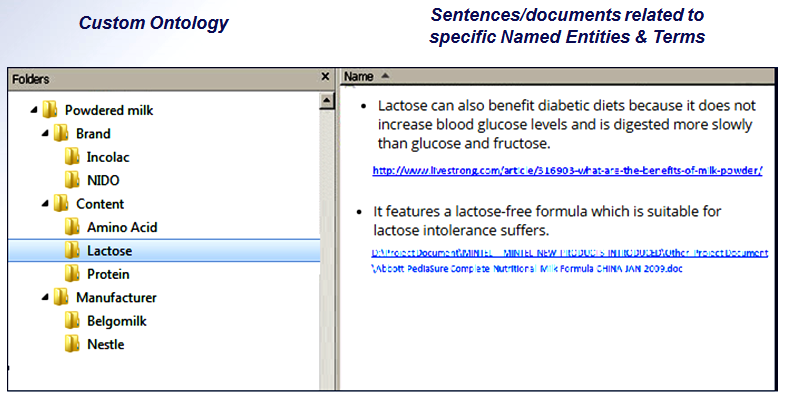
Beside the navigation, users can see the sentences that contain one or another concept. Moreover, it’s possible to track the frequency of any concept in the documents created at different times:
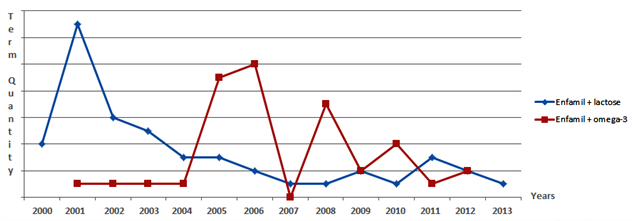
Implementation of knowledge management system is not an easy process. But our NLP experts can help you to do that with minimum expenses and within the shortest possible period of time. As a result, you’ll be able to use the intellectual resources, deeply hidden on your servers.
August 1, 2016
Back to Blog Main PageGet Started
API Usage Examples
- Sentiment Analyzer
- Named Entity Recognizer
- Summarizer
- Multi-Document Summarizer
- Comparator
- Clusterizer
- Natural Language Interface
- Preformator
- Language Recognizer
- SpellChecker
Intellexer Summarizer
Application based on Intellexer API that performs:
- Document summarization
- Concept mining
- Entity extraction
- Summary rearrangement according to the selected items